FAST SUPER RESOLUTION CONVOLUTIONAL NEURAL NETWORKS
Overview
FSRCNN (Fast Super-Resolution Convolutional Neural Network) is a model tailored for real-time image super-resolution. It utilizes a unique architecture with smaller filter sizes and an efficient sequence of convolutional and deconvolutional layers, which first extracts features, reduces dimensionality, and then upscales the image. This design achieves high-quality, high-resolution outputs with minimal computational cost, making FSRCNN suitable for fast, high-performance applications in super-resolution tasks.

Approach
- Firstly we started with learning basic concepts of Neural Networks and Machine Learning.
- With this knowledge we started the implementation of the handwritten digit recognition model (MNIST dataset) by a simple 2 layer ANN , using NumPy from scratch.
- Further we learned the basic concepts of Optimizers, Hyperparameter tuning, Convolutional Neural Networks and studied its various architectures.
- Then we implemented the MNIST model using the PyTorch framework (Firstly using a 2 layer ANN and then by using a Deep CNN architecture).
- Furthermore, we also implemented an object detection model based on the CIFAR-10 dataset using a Deep CNN architecture along with batch normalization and dropout regularization.
- Then we implemented a custom data loader to extract the raw High Res and Low Res images from the BSD-100 dataset which would be further used as train and test datasets for the implementation of SRCNN and FSRCNN.
- We implemented the SRCNN architecture in PyTorch for the BSD-100 dataset, taking reference for the architecture from the following research paper :- “Image Super-Resolution Using Deep Convolutional Networks”.
- Finally, we implemented the FSRCNN architecture for the same dataset. Reference from the following research paper :- “Accelerating the Super-Resolution Convolutional Neural Network”
Evaluation Metric and Loss Functions
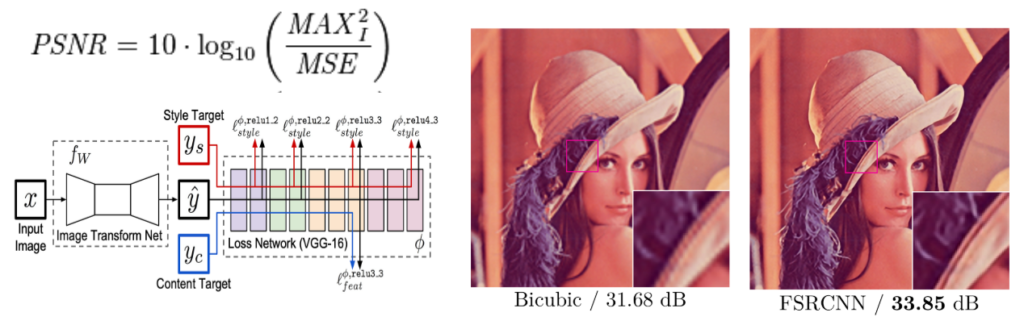
- Peak Signal-to-Noise Ratio (PSNR) is a metric that quantifies the quality of a reconstructed or compressed image by comparing the maximum possible signal power to the power of the noise, expressed in decibels (dB) on a per-pixel basis.
- Apart from the pixel-wise MSE loss used in the original paper, we have also used Perceptual Loss function as obtained from pre trained VGG-19 (Image Classification) model. The MSE loss between features extracted from 4 sequential ‘slices’ of the network is added to the pixel-wise MSE loss of the final image to yield a loss function that can handle problems like translation, tonal variance and can compare the structural similarity between images using high level features.
Model Architecture
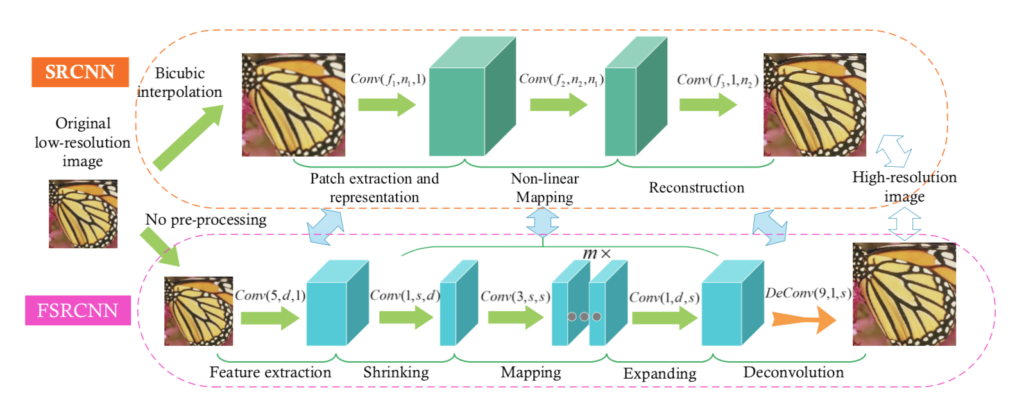
- FSRCNN can be decomposed into five parts feature extraction, shrinking, mapping, expanding and deconvolution. The first 4 layers are a convolution operation. The model can be viewed as an Hourglass-like architecture.
- Feature Extraction: FSRCNN performs feature extraction on the original LR image without interpolation. This operation can be represented by Conv(5, d, 1).
- Shrinking: In SRCNN the mapping step has high complexity due to size of the Low-res dimension feature vectors, hence a 1×1 convolution is used to reduce the size of the Low Resolution feature maps. This step can be represented by Conv(1, s, d).
- Non-linear mapping: The non-linear mapping step is the most important step, mainly affected by the number of filters used and the mapping depth (m). It can be denoted by the convolution operation Conv(3, s, s)
- Expanding: This layer is added to invert the effects of shrinking which was mainly added to reduce computational complexity. This layer needs to be used rather than directly reconstructing the High resolution image to avoid poor restoration quality. This step can be represented by Conv(1, d, s).
- Deconvolution: This layer upsamples and aggregates the previous features with a set of Deconvolution filters (which are basically an inverse operation of convolutions) to generate the final High resolution image. This layer can be represented by as DeConv(9, 1, d).
- Training: Just as similar to SRCNN , in FSRCNN the loss function can be calculated through a weighted combination of the pixel-wise MSE loss and the Low-level features based Perceptual Loss calculated using a pre-trained VGG-19 / 16 model.
Results

Use Cases of the Project
- Communication systems : Reducing transmission costs
- Signal processing: Sensor data enhancement (LiDAR, RADAR), autonomous driving and geological surveying
- Forensics and Legal investigations: Image and video evidence enhancement
- Denoising: Reconstruction of degraded images, like historical photos or damaged surveillance footage