Overview
This project showcases the training of a Reinforcement Learning (RL) agent using Proximal Policy Optimization (PPO) within a custom environment designed for the game Doom, utilizing the VizDoom library. The RL agent learns to interact with the game environment, developing effective strategies for navigation and survival.
Approach
To understand RL concepts, we first trained on various environments.
a)FrozenLake Environment:
For FrozenLake, we used Dynamic Programming, which quickly converged to an optimal solution in the deterministic setting. In contrast, Monte Carlo and SARSA(λ), better suited for model-free scenarios, required extensive exploration and hyperparameter tuning to perform well in the stochastic version.
Results:
b)MiniGrid Environment
We solved this environment using Monte Carlo, SARSA(λ), and Q-learning.
Q-Learning: Achieved rapid convergence in fully observable environments but struggled in partially observable ones due to its reliance on immediate state-action updates.
Monte Carlo: Trained the agent to navigate a partially observable grid world using a first-visit approach and an epsilon-greedy strategy. While effective in smaller grids, it required more episodes to converge than Q-learning.
SARSA(λ): Provided stable learning with eligibility traces that improved reward propagation. It outperformed Q-learning in partially observable settings but required careful tuning of the λ parameter.
Results:
Project Implementation
Environment Description
VizDoom is a Doom-based AI research platform for reinforcement learning from raw visual information. It allows developing AI bots that play Doom using only the screen buffer. Key features include:
- 3D first-person perspective.
- Partial observability (agent’s view is limited).
- Customizable resolution and rendering options,
- Various scenarios with different objectives (e.g., navigation, combat, survival).
- Customizable reward structure and action space.
References
Usage
- Run the training script: python doom.py This will initialize the Doom environment, set up the PPO model, and begin training.
- Training Options: Modify
timestepsandepisodesin the script to change the number of steps and episodes for training. Models are saved in theMODELS/PPOdirectory and logs are saved in thelogsdirectory for TensorBoard - Visualize Training (TensorBoard): After training starts, you can visualize the learning progress usingTensorBoard:
tensorboard --logdir=logs
Implementation
- Neural Network Architecture: PPO utilizes a policy network and a value network, both commonly structured as fully connected layers or CNNs, to process game frames and output action probabilities and value estimates.
- Advantage Function: PPO computes the advantage function using the difference between the estimated value and the observed rewards, allowing for effective updates of the policy.
- Clipping: The policy update incorporates a clipping mechanism to limit the change in the probability ratios, ensuring that updates are stable and do not deviate significantly from previous policies.
- Training: The agent collects experiences by interacting with the environment, using these experiences to calculate advantages, then updates the policy and value networks based on the collected data while applying the clipping mechanism.
Training
In any machine learning project training is the most important part.Here we enclosed how training changed after agent has more and more time spent.
Agent after 20K TIMESTEPS
Place here video of 20k
Agent after 50K TIMESTEPS
Place here video of 50k
Agent after 90K TIMESTEPS
Place here video of 90k
Results
Graph Between Episodic mean reward and Time steps
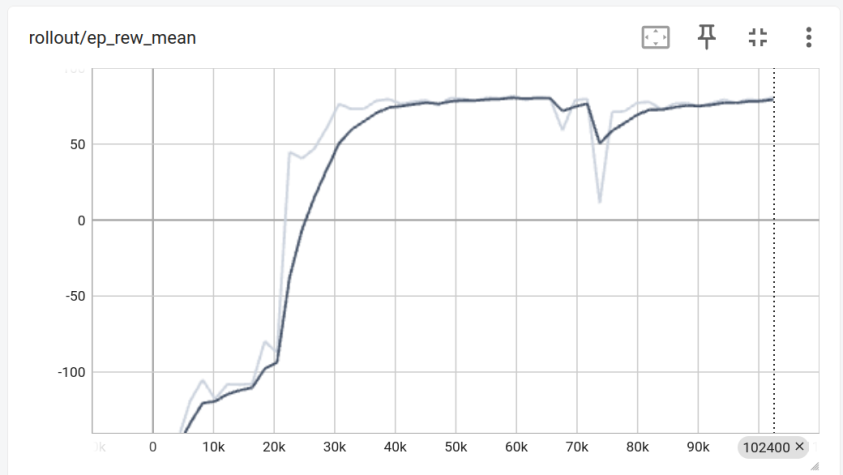
Graph Between Episodic mean length and Time steps
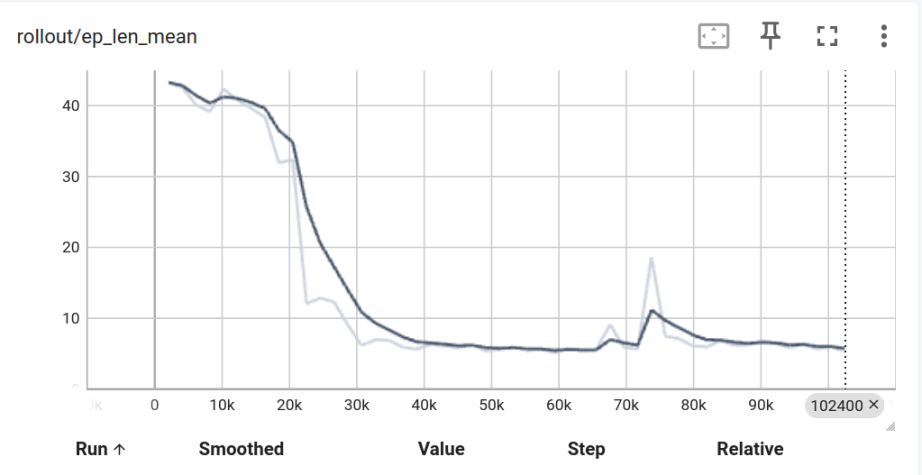
Team Members
Mentors