Overview
The project is an attempt to solve Classic Snake Game using Reinforcement Learning Tabular method i.e. Q-learning. The goal of the agent, the snake, is to maximize cumulative reward which it does by generating a table called Q-table which is used to decide action for each state. The values in this table are called state-action values as they represent the value of performing a particular action in a particular state. The state is information that an agent receives for a particular situation that is used to estimate future outcomes. The policy tells us about the behavior of the agent. Here the agent uses the Q-table to pick the most suitable action for the current state which returns a reward after each action.Algorithm used-
Epsilon greedy policy improvement
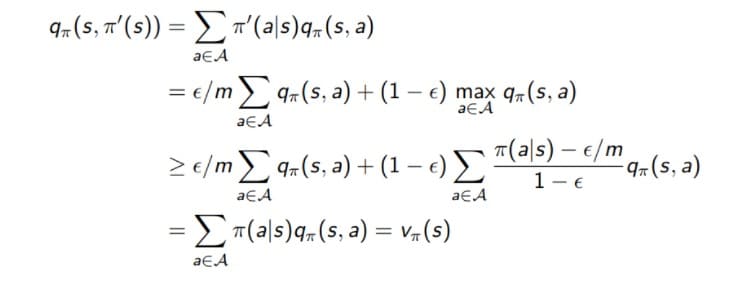
Q-Learning

Approach
Snake is assumed to be near-sighted. Its state has four parameters-
- The direction of food relative to snakehead.
- Presence of obstacle or wall in the immediate left of snake’s head.
- Presence of obstacle or wall in the immediate left of snake’s head.
- Presence of obstacle or wall in the immediate left of snake’s head.
Action space has been re-initialized so that it will be relative to the head of the snake.
Reward function-
- +1 for eating the food.
- -1 for hitting its body or wall.
Except for the above two conditions, the default value of the reward function is 0.
Result
Training for 5000 episodes 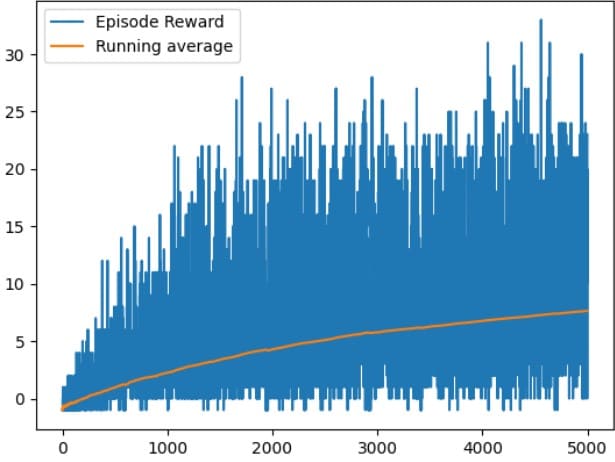 | Testing policy 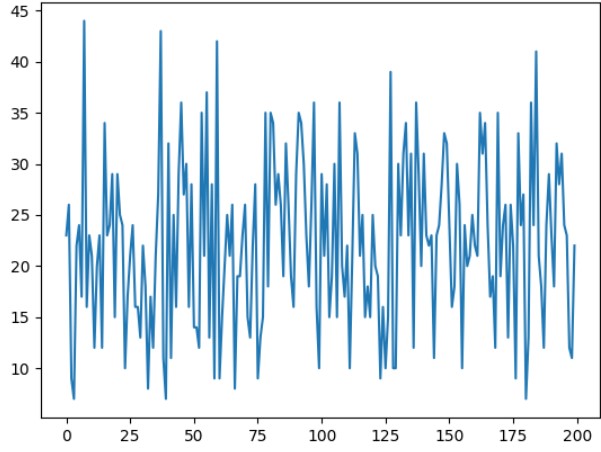 |
Applications
After training, the obtained policy can be used in different modes such as 2 or 3 snakes in the same environment simultaneously or in a custom environment with obstacles randomly placed.
 3 snakes in 30X30 environment 3 snakes in 30X30 environment |
Conclusion
1st episode  | After 1000 episodes of training 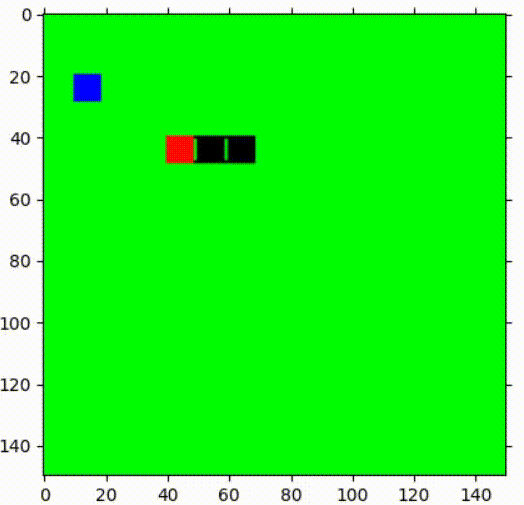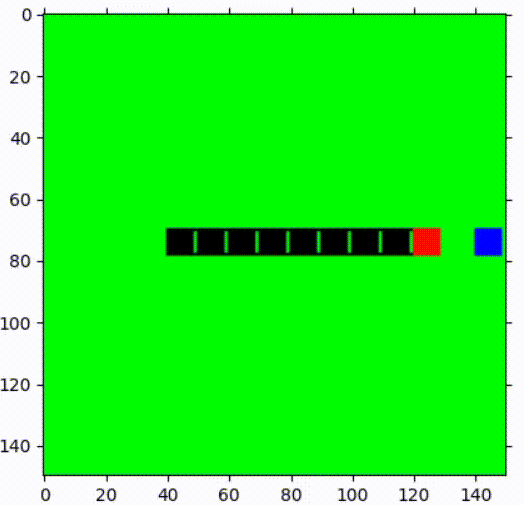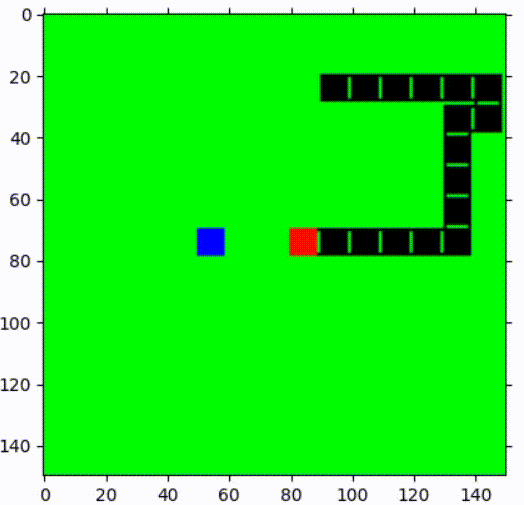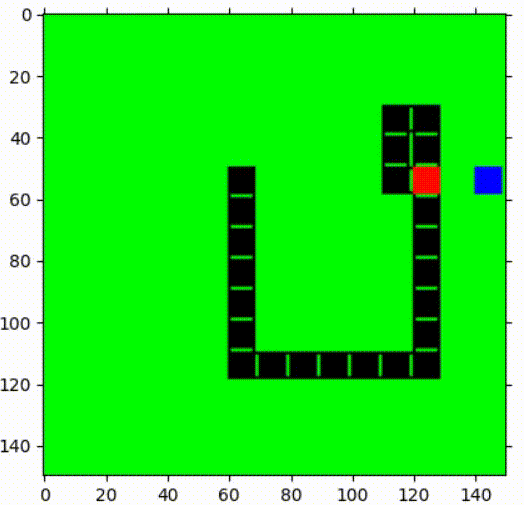 |
Note
With this approach an optimal policy cannot be obtained because the snake can dodge only immediate obstacles, thus there are high possibilities that the snake will be entangled in its own body eventually cornered by obstacles from each side which will lead to the death of the snake.
In the testing graph, it can be observed that the rewards are not consistent. This is due to the random position of the food each time and which affects the early entanglement of the snake.
GitHub Repository
Tools and Libraries used
 Python Python |  |
 Matplotlib Matplotlib |  |
| Team Members:Harsh SharmaOm BhisePoojan GandhiVinita LakhaniAhmed HamzahShubham Vishwakarma | Mentors:Tanmay PathrabeAkshansh MalviyaAneesh Shetye |