Overview
The project Automatic Speaker Recognition (referred to as ASR) is designed to recognize and distinguish between multiple voices of different persons. A very large dataset of various speakers is used and every single audio sample is tested with the existing audio samples and matched with the audio sample whose features are mostly matching. Finally, the accuracy of these results is checked to know the working of the project.
Abstract
From the very famous voice assistants designed by the sophisticated developers of the world, SIRI and ALEXA have been ruling the signal processing world for many years. This project is the inspiration from those ideas to develop a simple project of Speaker Recognition which is the tiny yet crucial part of these mentioned assistants. We at IvLabs, gave a try in the world of Digital Signal Processing to develop this project with the help of very famous MFCC, LPC, and LBG algorithms
Algorithm
MFCC and LPC for Feature Extraction
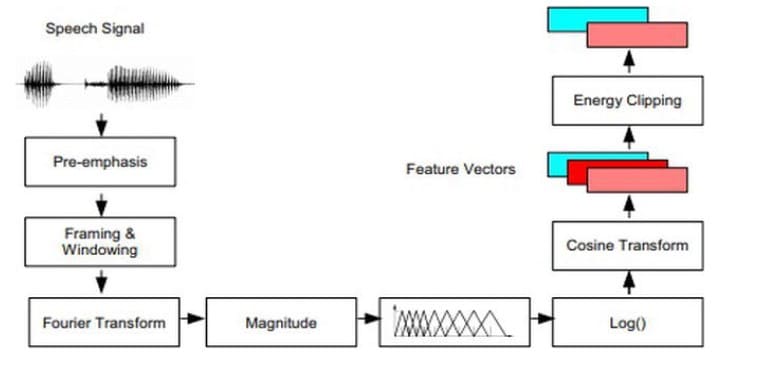
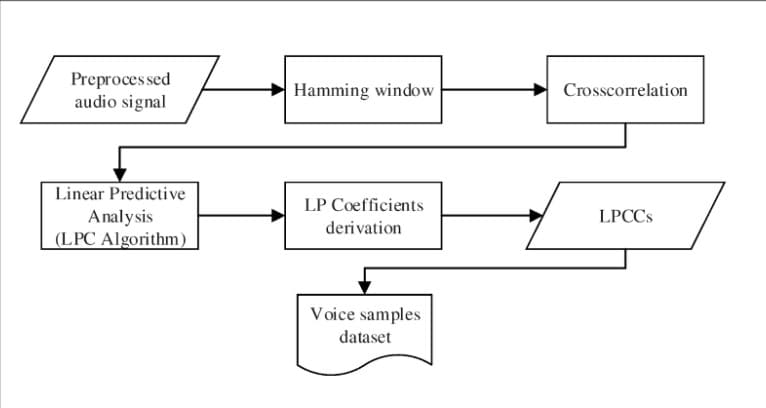
LBG and KMeans Clustering for Feature Matching
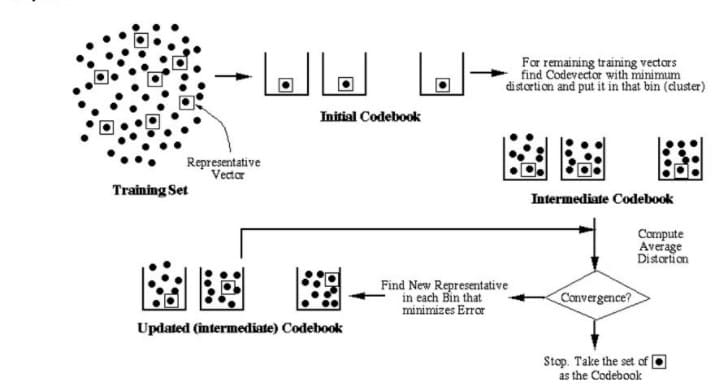
Approach
- A small dataset of 8 different speakers is taken into consideration and to start with the input signal is framed into shorter parts followed by windowing.
- In nature human hearing is not linear, filters spaced linearly at low frequencies and logarithmically at high frequencies are used to capture the phonetically important characteristics of speech.
- MFCC and LPC coefficients are calculated and estimated spectrograms are used to extract the important features of the audio.
- After the feature extraction, they are matched with the most suitable speaker in the training set.
- During training, using the LBG algorithm a codebook is derived representing features of speakers. These codebooks are unique to each speaker.
- To identify a speaker, the distance (or distortion) of the speaker’s features from all the trained codebooks is calculated. The codebook that has minimum distortion with the speaker’s features is identified.
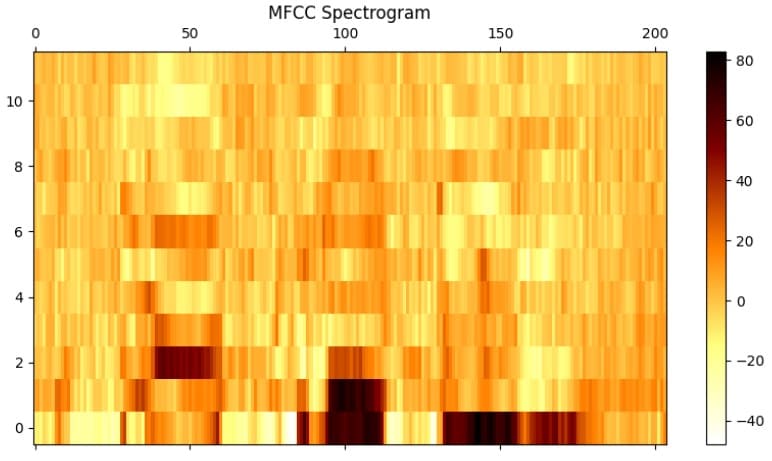
Result
GitHub Repository
Possible Extensions:
- Speaker Recognition with added noise and disturbance
- Recognition of Multiple Speakers
| Team Members:Dweeja ReddyJagathAyush Varma Gautam Tahilyani Aditya Undrikar | Mentors: Sibam Parida Thanmay Jayakumar Luqman Farooqui |