Overview
Autonomous Driving Using Deep Reinforcement Learning implements an end-to-end PPO agent that learns to follow lanes and control speed in the gym-donkeycar simulator using only raw 120×160 RGB camera input. Through a progressive learning path—from classic RL algorithms to CNN vision processing and Actor-Critic methods—the agent masters continuous steering (-5 to +5) and throttle (0-1) control. A carefully designed reward function balances lane centering and forward velocity while penalizing collisions. PPO’s clipped objectives, GAE advantages, and sample efficiency enable stable training, achieving smooth lap completion and generalization to challenging mountain tracks purely from visual observations.
Approach
- RL Fundamentals – Implemented value iteration, policy iteration, Monte Carlo, SARSA, Q-learning, and exploration strategies on FrozenLake and MiniGrid environments to master agent learning dynamics.
- Deep Learning Foundations – Built neural networks from scratch using NumPy (forward/backward propagation), then implemented CNNs and deep models in TensorFlow to understand spatial feature extraction critical for lane detection.
- Deep RL Transition – Studied policy-gradient methods and Actor-Critic architectures, establishing the theoretical foundation for PPO’s suitability in continuous control problems.
- Autonomous Driving Agent – Integrated gym-donkeycar simulator, CNN vision backbone, and PPO Actor-Critic network. The agent controls continuous steering (-5 to +5) and throttle (0-1) using a reward function that balances lane centering, speed, collision avoidance, and track stability.
Environment: gym-donkeycar
Action Space (Continuous)
| Action | Range |
|---|---|
| Steering | -5 to +5 |
| Throttle | 0 to 1 |
Observation Space
- 120×160 RGB camera frame
- Contains road edges, curvature, and background context
- Used as direct input to the CNN network

Reward Function
The reward encourages smooth and safe driving:
- Strong penalties for collisions
- Penalties for going off-track (max cross-track error reached)
- Positive reward proportional to centeredness and forward velocity
This motivates the agent to balance both lateral stability and speed.

Proximal Policy Optimization (PPO)
PPO is the reinforcement learning algorithm used to train the driving agent.
It is well suited for continuous control problems like steering and throttle regulation.
PPO follows an Actor-Critic design:
Actor
- Receives CNN features
- Outputs continuous steering and throttle
- Represents the policy that selects actions
Critic
- Estimates the value of the current state
- Helps guide policy updates through advantage estimation
Why PPO Works Well for Driving
Driving requires stable, incremental learning because sudden policy changes lead to crashes or inconsistent behavior.
PPO addresses this through three main ideas:
1. Clipped Objective
PPO restricts how much the new policy can deviate from the old policy during updates.
This prevents unstable jumps in behavior and keeps training controlled and reliable.
2. Efficient Advantage Estimation
Generalized Advantage Estimation (GAE) is used to compute how much better a chosen action was compared to expected performance.
This results in smoother and more informative updates.
3. Sample Efficiency
PPO reuses collected experiences multiple times via mini-batch optimization, making training more efficient while preserving stability.
Summary of PPO in this Project
- CNN extracts lane-related features from camera frames
- Actor outputs continuous control commands
- Critic estimates long-term future reward
- PPO updates the policy gradually using clipped ratios
- Training remains stable across thousands of steps
This combination allows the agent to learn consistent and robust driving behavior from visual input alone.
Algorithm Pipeline (Step-by-Step)
- Capture camera frame
- Preprocess and pass through CNN
- Extract features
- Actor produces steering and throttle
- Environment applies the action
- Reward and next state are returned
- Transition stored in rollout buffer
- PPO performs policy and value updates
- Loop continues across many timesteps
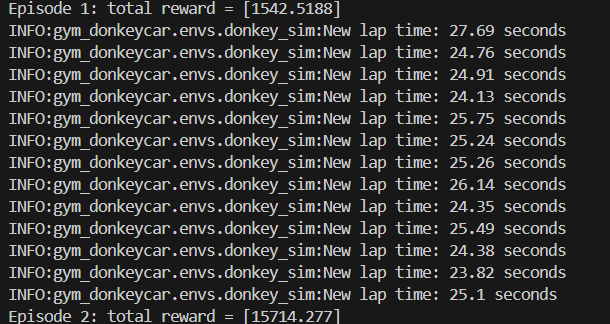
Raining and Results
Learning Progress
- Early stages: frequent off-track events
- Mid training: better lane centering, improved curvature handling
- Final stages: smooth lane-following with stable throttle control

Mountain Track Generalization
A more challenging test track with sharp turns and elevation.
The trained agent adapts and navigates reliably after extended training.

Project Outcomes
The trained agent successfully:
- Maintains lane position
- Controls speed effectively
- Completes full laps without intervention
- Learns solely from raw camera input
- Uses PPO for stable and robust continuous control
Trained Models and Video Results
Real-World Use Cases
- Autonomous Vehicles: Lane-following, speed control, and safe navigation using camera-based policies.
- Robotics: Path planning and real-time control for mobile robots in warehouses and factories.
- Smart Transportation: Traffic optimization, adaptive cruise systems, and intelligent lane assistance.
- Sim-to-Real Transfer: Safe training in simulators before deploying in physical environments.
- Drones: Stable autonomous flight, navigation, and environment-aware control.
- ADAS Systems: Vision-based alerts, steering assistance, and driver-support features.
- Research & Education: Benchmarking RL algorithms and studying vision-based continuous control.