Objective
This project focuses on training an AI agent to land a rocket safely in the ROCKET LANDER environment, similar to how SpaceX lands their reusable rockets. We’ll use Deep Reinforcement Learning (DRL) techniques to teach our rocket to make landing decisions on its own. Our goal is to create an AI that can control a simulated rocket and guide it to a successful landing. The AI will:
- Learn through trial and error
- Make decisions about engine thrust and orientation
- Adapt to changing conditions during descent
Overview
What is reinforcement learning?
- Reinforcement Learning is a type of machine learning where an agent learns to make decisions by interacting with an environment. The agent takes actions, receives rewards or penalties, and learns a policy (a strategy) to maximize its total reward over time.
- Imagine training a dog — you give it a treat when it does something right, and nothing when it doesn’t. Over time, it learns what actions get rewards.
- In RL, the agent is that “dog,” the environment is the world it interacts with, and rewards are the treats (or penalties)
- RL lets AI learn from trial and error instead of being told what to do — it becomes more autonomous and adaptive.
Approach
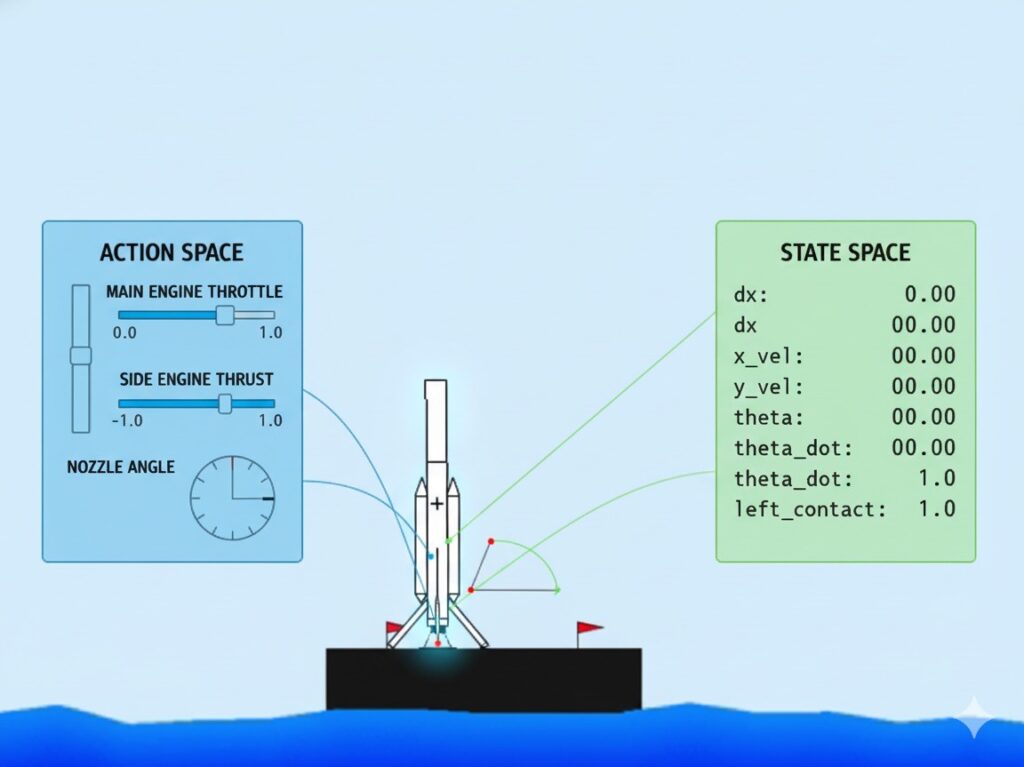
🌌 Environment Description
The custom environment simulates a 2D rocket controlled via thrust and torque.
It provides continuous feedback about position, velocity, and contact status.
Termination Conditions:
- ✅ Landed successfully
- 💥 Crashed or out of bounds
- ⛽ Fuel exhausted
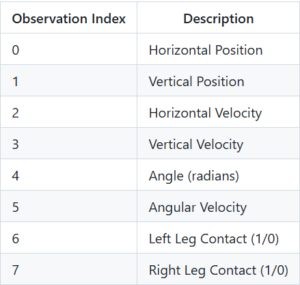
🎮 Action & State Spaces
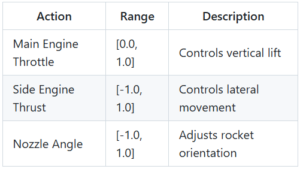
The state space is continuous (8-dimensional), allowing the policy to observe smooth dynamics of flight.
🧮 Reward Function
The reward function encourages safe, stable, and fuel-efficient landings.
[ R_t = \frac{(S_t – S_{t-1})}{10} – 0.3 \times (\text{main_power} + \text{side_power}) ]
Terminal Rewards:
- +10 → Landed safely
- −10 → Crashed / Out of bounds
Penalties:
- Upward velocity → −1
- Fuel usage → proportional penalty
This formulation uses a potential-based shaping function to stabilize learning and ensure smooth policy convergence.
⚙️ Training & Hyperparameters
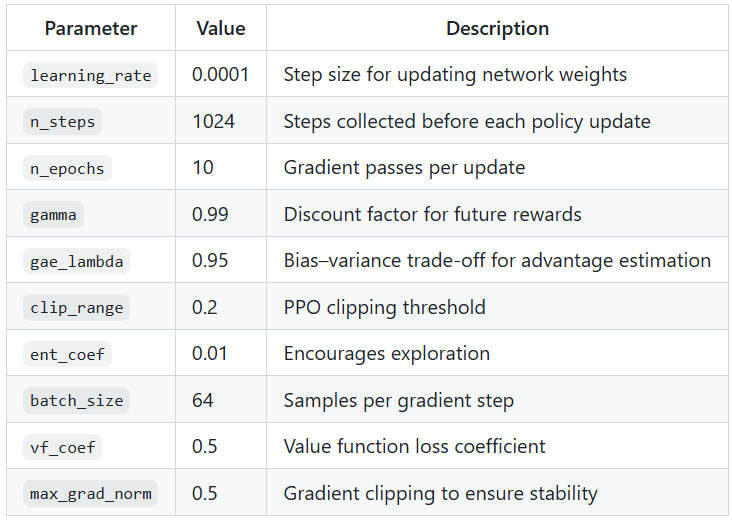
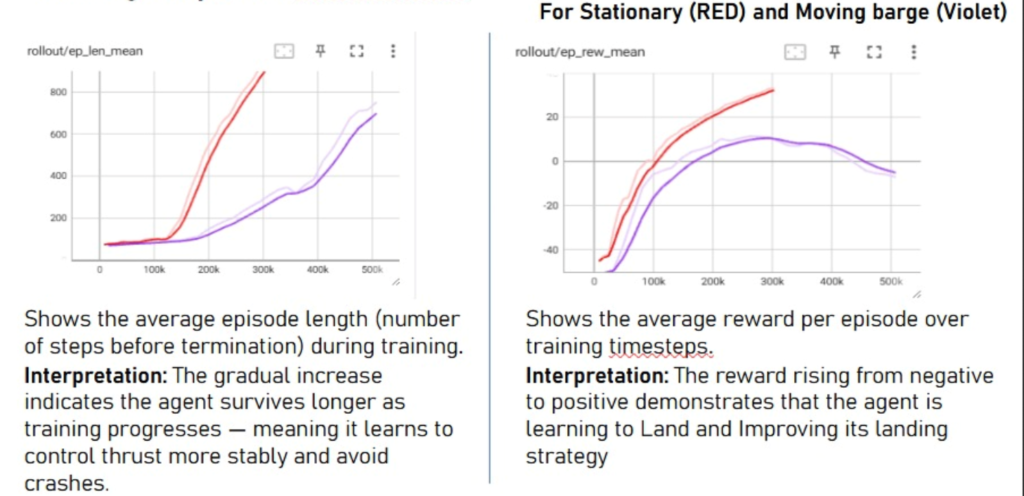
Graphs
DRL
Why integrate deep learning?
- Traditional RL algorithms like monte carlo or TD learning require storing a Q-table.
- The rocket lander environment has a continuous action and state space.
- Neural networks make computation faster and easier.
Algorithm
A Brief Introduction to PPO
- It uses two neurak networks – 1) The actor network and 2) The critic network
- The actor or the policy network is used to output the probabilities of various actions from a state.
- The critic or value network estimates the total expected return from the state.
- The above estimated value is backpropagated through the critic network.
- The policy network is updated after clipping these estimated values.
How does PPO work in our case?
- Actor Network: takes state → outputs action probabilities (Throttle, Side Thrust, Angle).
- Critic Network: takes same state → outputs single scalar value (predicted total reward).
- Each of these networks has 8 neurons (state vector) in their input layer
- The actor network has 3 output neurons (continuous action space outputs)
- The critic netwrok has one neuron i.e., the vakue estimate
- Both network shares similar architecture but separate weights
- Actor selects optimal thrust commands while the critic evaluates them
Advantages of implementing using PPO:
- A dense and high variance reward function is designed to take into consideration the complex physics of the environment. The critic network makes sure that these noises do not enter the policy network.
- A single nad batch of data may revert all previous learning. Clipping limits ensure that this doesn’t happen and guarantee a smoother and more reliable convergence.
- Both the action space and observation space are in terms of 3 dimensional floating point box. Discretization may lead to loss of accuracy. However, neural networks solve this problem by allowing us to incorporate the floating values into out training.
Results
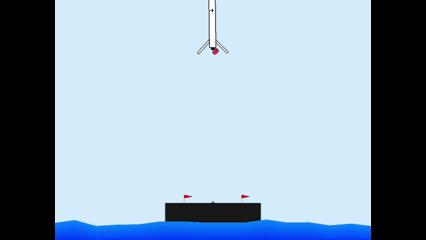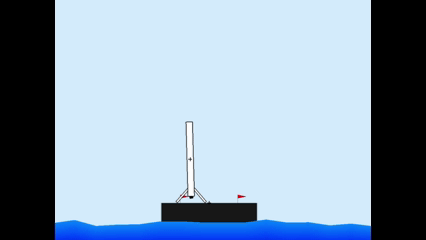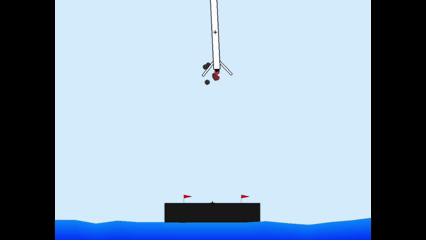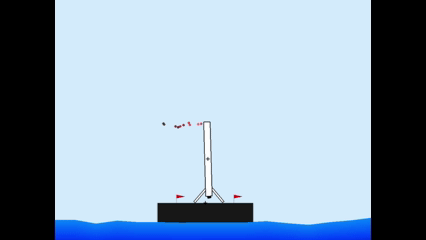
Members
- Tvisha Mehta
- Ishan Agrawal
- Raj Patil
Mentors
- Aarsush Sinha
- Akash Tiwari
- Atharv Kulkarni
- Anuj Sidam